Reactor 활용한 Notification 구축 POC

팀내 공유 자료
배경
- 최근 쇼핑몰 입점이 늘어나면서 쇼핑몰 어드민의 엑셀 다운로드 요청이 급증했고, 이로 인해 서버가 불안정해지는 문제가 발생
- 이를 해결하기 위해 Kafka Consumer를 활용한 비동기 엑셀 생성 방식으로 전환한 결과 서버 장애 해소
- 하지만 비동기 처리 특성상 고객이 다운로드 완료 시점을 즉시 알 수 없어, 고객 문의(CS)가 오히려 증가하는 새로운 문제가 발생
- 약 30만의 회원 엑셀 다운로드시 약 8분이상 소요(DB SELECT -> Excel 전환 -> Zip압축+암호화)
요구사항 정리
- 엑셀 다운로드 완료 알림
- 다양한 알림 유형 지원
- 주문발생, 클레임발생, 1:1문의, 상품승인, 상품문의, FDS 탐지
- 어드민 모바일 푸시(FCM)
- 대상별 알림 발송
- 몰별 알림, 운영자별 알림, 전체 알림, 파트너 알림
- 오프라인 지원 및 영속성
- 클라이언트 미접속 시에도 알림 보관
- Dooray Stream과 같은 타임라인 형태의 저장소 구성
전제조건
- EDA 기반 구현 - 이벤트 발생 시 Message Broker를 통해 실시간으로 클라이언트에 메시지 전달
- 도메인 간 결합도 최소화 - 각 도메인은 메시지 발행만 담당하며, Notification 시스템과의 커플링 방지
- MSA 서비스 독립성 - 다른 MSA 서버들과 완전히 독립적으로 동작
- Reactive 프로그래밍 - 비동기 논블로킹 방식으로 구현
- 독립적인 서비스 구성 - Spring Cloud Gateway를 거치지 않는 별도 도메인 서버 구성
- 인증 및 캐싱 전략 - Admin 토큰/정보 기반 메시지 대상 구분, 로컬 캐시 적극 활용
사전조사
HTTP Polling
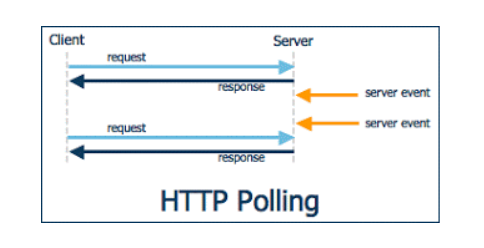
HTTP Polling은 클라이언트가 서버에 주기적으로 HTTP 요청을 보내서 새로운 데이터나 상태 변화를 확인하는 통신 방식
장점
- 구현이 간단하고 직관적
- 방화벽이나 프록시 환경에서도 잘 동작
- HTTP 표준을 그대로 사용
단점
- 폴링 주기가 짧으면 불필요한 네트워크 트래픽 발생
- 폴링 주기가 길면 실시간이 아님
- 서버 응답이 변하지 않으면 리소스 낭비
http 1.1에서는 keep-alive가 default이며 모든 요청이 connectionless는 아님

Long Polling
polling과 통신방법은 같으며 요청을 받은 서버는 메세지를 전달할수 있을 때까지(timeout될때까지) 무한정 커넥션을 종료하지 않고 메세지를 전달할수 있을때 응답을 준다.
장점
- 항상 연결이 되어있어서 polling보다는 리소스 절약
- 거의 실시간에 가깝다
- HTTP 표준을 그대로 사용
단점
- 데이터가 수시로 바뀔경우 polling보다 많은 리소스 낭비
- 호출 주기가 없기 때문에 응답이 오면 다시 서버로 요청
Server-Sent Events (SSE)
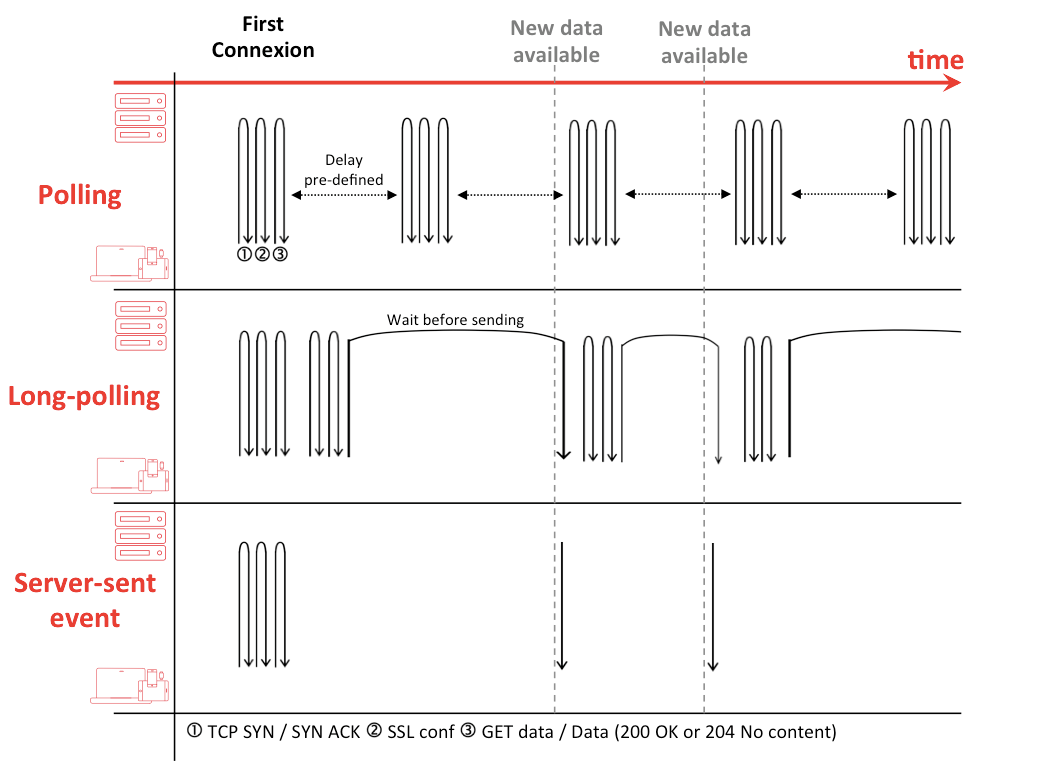
- 클라이언트는 메세지를 구독하고 서버는 이벤트 발생시 클라이언트로 푸시한다. (서버 -> 클라 단방향)
- response header의 content-type: text/event-stream이 추가되어야 하며 response body의 format은 아래와 같다.
response payload
# multiline data
data: first line\n
data: second line\n\n
# JSON Data
data: {\n
data: "msg": "hello world",\n
data: "id": 12345\n
data: }\n\n
JSON 젹렬화가 복잡해 보이지만 Spring의 Content Negotiation Strategies을 믿어보자.
장점
- 통신 리소스 절약
- 전통적인 HTTP를 이용하며 구현 심플
단점
- XHLHttpRequest가 아닌 EventSource web api로 구현
- 단방향 통신
https://developer.mozilla.org/ko/docs/Web/API/EventSource/EventSource
Websocket
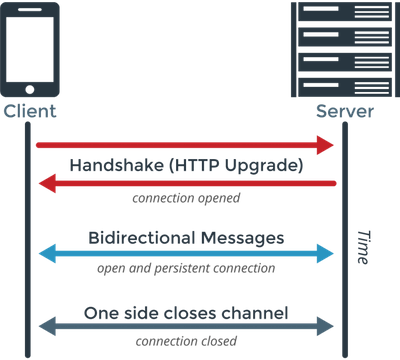
- 2011년 표준화되었으며 양방향 통신
- http://가 아닌 ws://프로토콜을 사용하며 80(ws://), 443(wss://)포트 사용
- handshake는 위와 동일하게 http통신으로 이루어지며 handshake수립후에는 ws로 양방향 통신한다
장점
- 웹표준이며 SSE보다 브라우저 호환성이 더 좋다.
- 양방향이다.
단점
- 서버와 클라이언트 모두 receive와 send를 구현해야 하며 전통적인 웹개발 방식으로는 구현이 어렵다.
https://developer.mozilla.org/ko/docs/Web/API/WebSocket
구현
repo : https://github.com/chk386/notifications
기술스택
- language : kotlin
- reactor, coroutine, reactive kafka, webflux functional endpoint
- message broker : kafka
- framework : springboot 2.4.4
- client : ES6, vanillaJS, EventSource, Websocket
- container : docker-compose (zookeeper, kafka, kafka-ui)
- build tool : gradle kotlin DSL
- dockerizing : spring boot maven plugin (bootBuildImage)
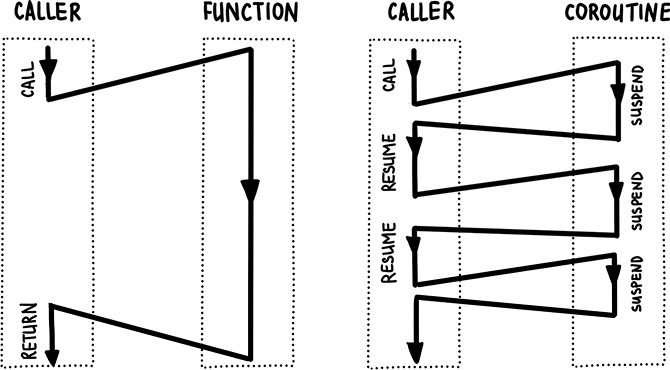
핵심 키워드 : hot
cold publisher
Mono/Flux는 subscribe하지 않으면 아무일도 일어나지 않는다. 대부분 webflux에서 subscribe를 대신 처리하고 있다.
hot publisher
subscribe 하기전 데이터를 생성할 수 있고 N개의 subscriber가 존재할수 있다. Notification 서버가 최초 기동할때 hot publisher를 메모리에 올려두고 SSE, Websocket 요청시 hot publisher를 구독하여 서버 이벤트를 클라이언트로 푸시할수 있다.
Sinks
reactor 3.4.0 이전에는 FluxProcessor, MonoProcessor, UnicastProcessor등을 이용하였으나 deprecated
The Sinks categories are:
1. many().multicast(): a sink that will transmit only newly pushed data to its subscribers, honoring their backpressure (newly pushed as in "after the subscriber’s subscription").
2. many().unicast(): same as above, with the twist that data pushed before the first subscriber registers is buffered.
3. many().replay(): a sink that will replay a specified history size of pushed data to new subscribers then continue pushing new data live.
4. one(): a sink that will play a single element to its subscribers
5. empty(): a sink that will play a terminal signal only to its subscribers (error or complete), but can still be viewed as a Mono<T> (notice the generic type <T>).
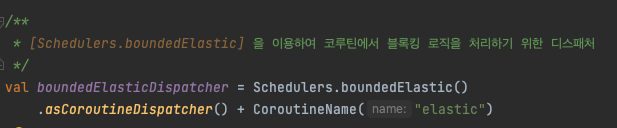
Sinks.Many< T >.multicast().onBackpressureBuffer()

Sinks.many().multicast().onBackpressureBuffer()
시스템 구성
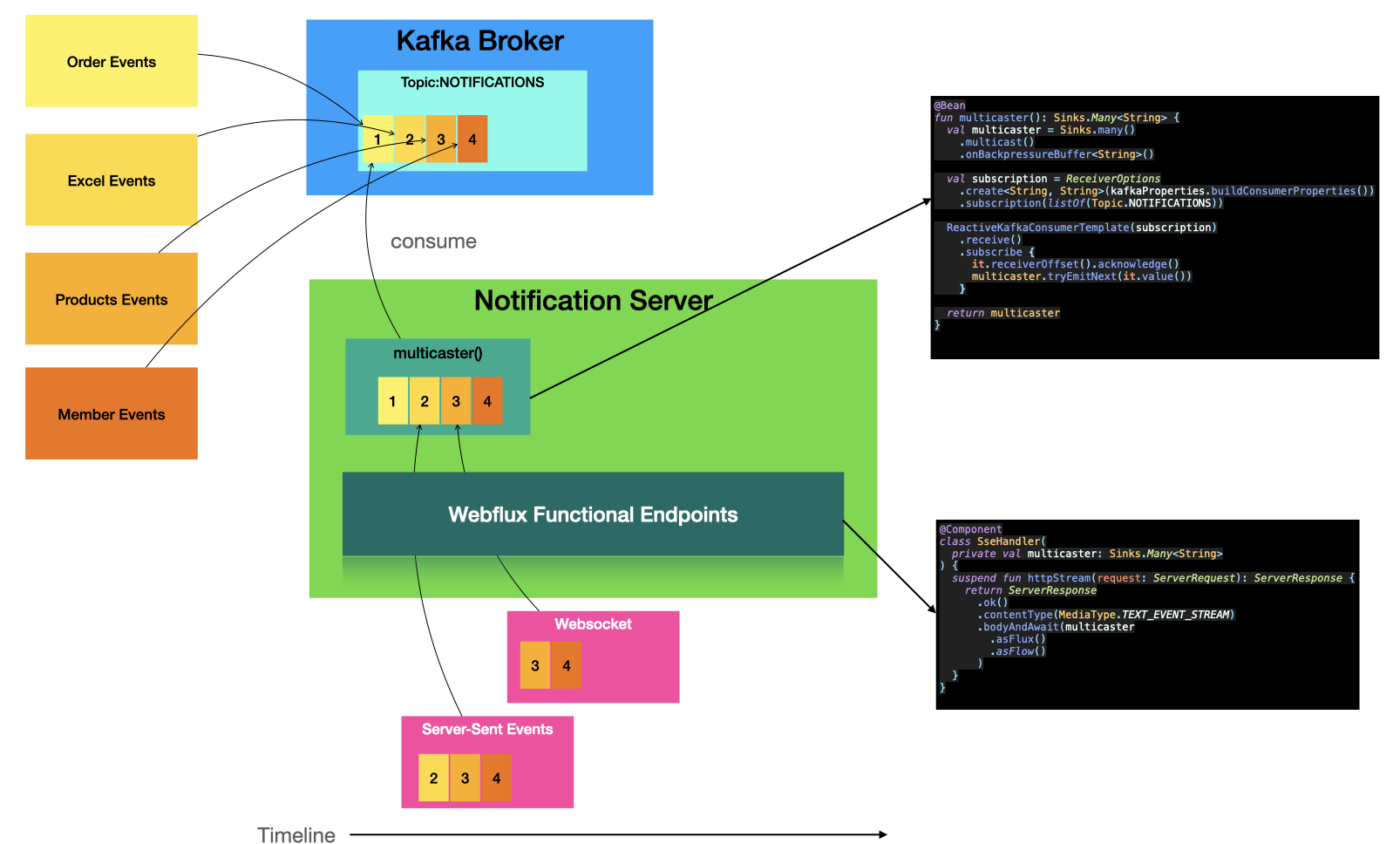
코드
// 메인 클래스
@SpringBootApplication
@EnableWebFlux
class NotificationsApplication {
@Bean
fun coRoute(sseHandler: SseHandler): RouterFunction<ServerResponse> {
return coRouter {
GET("/notifications", sseHandler::httpStream)
GET("/produce", sseHandler::produce)
}
}
/**
* @see <a href="https://docs.spring.io/spring-framework/docs/current/reference/html/web-reactive.html#webflux-websocket-server-handler">참고</a>
*/
@Bean
fun handlerMapping(websocketHandler: WebsocketHandler, sampleHandler: SampleHandler): HandlerMapping {
val map = mapOf(
"/ws" to websocketHandler, "/ws2" to sampleHandler
)
val order = -1 // before annotated controllers
return SimpleUrlHandlerMapping(map, order)
}
@Bean
fun handlerAdapter() = WebSocketHandlerAdapter()
@Bean
@Profile("default")
fun run(producer: ReactiveKafkaProducerTemplate<String, String>): ApplicationRunner {
return ApplicationRunner {
while (true) {
println("메세지를 입력해주세요.")
producer.send(Topic.NOTIFICATIONS, GenericMessage(readLine()!!)).subscribe()
}
}
}
}
- 웹소켓 핸들러를 router에 등록, 엔드포인트는 "/ws", "/ws2"로 등록
- 테스트 용으로 터미널에서 표준 입력(키보드)시 카프카로 토픽 전송 (메세지 전파)
// 웹소켓 핸들러 구현
@Component
class WebsocketHandler(
private val producer: ReactiveKafkaProducerTemplate<String, String>,
private val multicaster: Sinks.Many<String>
) : WebSocketHandler {
override fun handle(session: WebSocketSession): Mono<Void> {
val input = session
.receive()
.doOnNext {
producer.send(Topic.NOTIFICATIONS, it.payloadAsText).subscribe()
}.then()
val output = session
.send(multicaster
.asFlux()
.filter { it.contains("all:") || it.startsWith(getId(session.handshakeInfo.uri)) }
.map(session::textMessage)
)
return Mono.zip(input, output).then()
}
private fun getId(uri: URI): String {
return UriComponentsBuilder
.fromUri(uri)
.build()
.queryParams["id"].orEmpty()[0]
}
}
- WebSocketHandler를 상속받아 handle 구현
- 웹소켓은 양방향 통신이기 때문에 input, output을 정의해야 한다.
- input에서는 전달 받은 payload text를 카프카 토픽으로 발행 한다.
- output에서는 kafka에서 받은 메세지들을 flux로 변환 후 구독자에게 메세지를 브로드 캐스트한다.
// kafka config
@Configuration
@EnableKafka
class KafkaConfiguration(private val kafkaProperties: KafkaProperties) {
@Bean
fun multicaster(): Sinks.Many<String> {
val multicaster = Sinks.many()
.multicast()
.onBackpressureBuffer<String>()
multicaster.asFlux()
.subscribe { println("consumer -> Sinks.many().multicast() => $it") }
consume(multicaster)
return multicaster
}
@Bean
fun produce(): ReactiveKafkaProducerTemplate<String, String> {
return ReactiveKafkaProducerTemplate(
SenderOptions.create(
kafkaProperties.buildProducerProperties()
)
)
}
private fun consume(multicaster: Sinks.Many<String>) {
ReactiveKafkaConsumerTemplate(
ReceiverOptions
.create<String, String>(kafkaProperties.buildConsumerProperties())
.subscription(listOf(Topic.NOTIFICATIONS))
)
.receive()
.doOnNext { it.receiverOffset().acknowledge() }
.subscribe { multicaster.tryEmitNext(extractMessage(it)) }
}
private fun extractMessage(it: ReceiverRecord<String, String>) =
if (it.value().contains(":")) {
it.value()
} else {
"all:${it.value()}"
}
}
object Topic {
const val NOTIFICATIONS = "BACKOFFICE-NOTIFICATIONS"
}
- 메세지 전달(토픽 발생)과 메세지 컨슘(메세지를 multicaster에게 전달)
local
- git clone https://github.com/chk386/notifications
- docker-compose up
- localhost:8081 : kafka UI
- localhost:9092 : broker
- localhost:2181 : zookeeper
- gradle boot run (또는 idea에서 NotificationsApplication.kt 실행
nhn cloud
- dockerizing
gradle bootBuildImage --imageName=shopby-notification
docker login # docker hub 계정입력
docker tag shopby-notification ${본인의 dockerhub ID}/notification
docker image push ${본인의 dockerhub ID}/notification
- docker
# 인스턴스에 ssh 서버접속 후 실행
docker-compose -f docker-compose-nhncloud.yml up
docker run -d -e "SPRING_PROFILES_ACTIVE=cloud" -p 8080:8080 chk386/notification
# 카프카 토픽 & 메세지 생성시
docker exec -it kafka /bin/bsh
# 토픽생성
/bin/kafka-topics --create --topic BACKOFFICE-NOTIFICATIONS --bootstrap-server localhost:9092
# 토픽정보
/bin/kafka-topics --describe --topic BACKOFFICE-NOTIFICATIONS --bootstrap-server localhost:9092
# procude
/bin/kafka-console-producer --topic BACKOFFICE-NOTIFICATIONS --bootstrap-server localhost:9092
# consumer
/bin/kafka-console-consumer --topic BACKOFFICE-NOTIFICATIONS --bootstrap-server localhost:9092
# 토픽 삭제
/bin/kafka-topics --delete --topic BACKOFFICE-NOTIFICATIONS --bootstrap-server localhost:9092
생각해봐야 할 것들
- 유실을 허용한다면 redis pub/sub도 괜찮은 방법인듯 하다
- 현재 백오피스 고객이 2000을 넘지 않기에 Notification서버 1대로 운영이 충분히 가능
- 만약 동접이 더 많아지면 웹소켓 서버를 여러대 두어 라우팅 전략 짜야함
- reactive 드라이버를 지원하는 mongoDB의 change stream기능도 고려해볼 필요가 있다. 실시간성과 영속성을 모두 만족 링크
- 앱 서드 파티 개발사에 notification api 개방
참고자료
- What is Http : https://www.concurrency.com/blog/june-2019/why-http-is-not-suitable-for-iot-applications
- Keep-Alive : https://velog.io/@yvvyoon/keep-alive
- Long Polling : https://medium.com/ably-realtime/websockets-vs-long-polling-55bdf09a7268
- Server Sent Events: https://systemdesignbasic.wordpress.com/2020/02/01/12-long-polling-vs-websockets-vs-server-sent-events/
- Send JSON Data : https://hamait.tistory.com/792
- Websocket : https://kouzie.github.io/spring/Spring-Boot-%EC%8A%A4%ED%94%84%EB%A7%81-%EB%B6%80%ED%8A%B8-WebSocket/#websocket-client
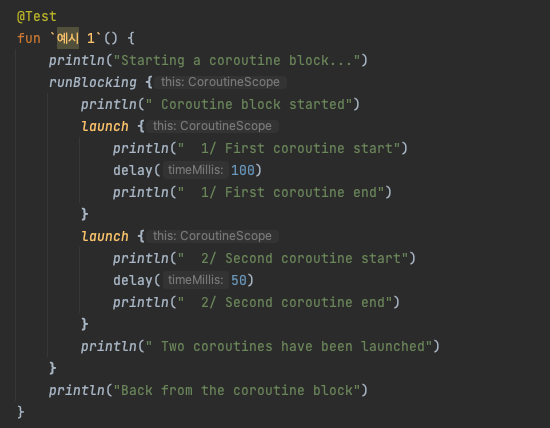
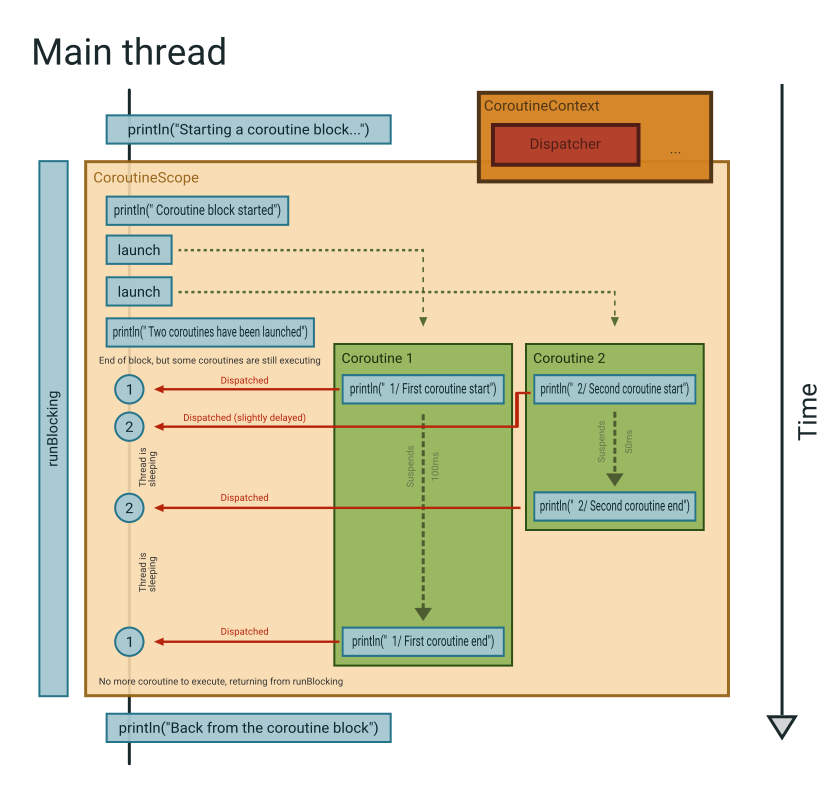
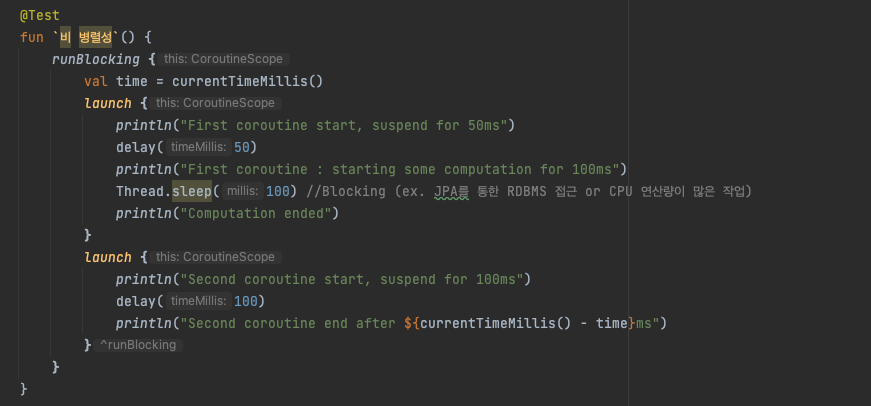 결과
결과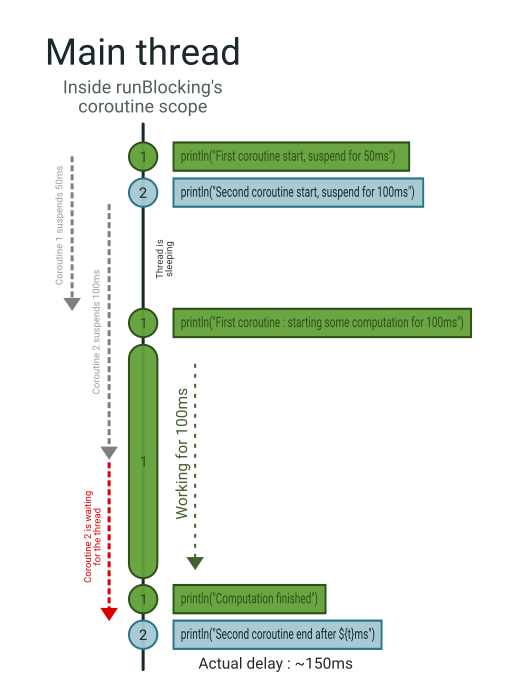
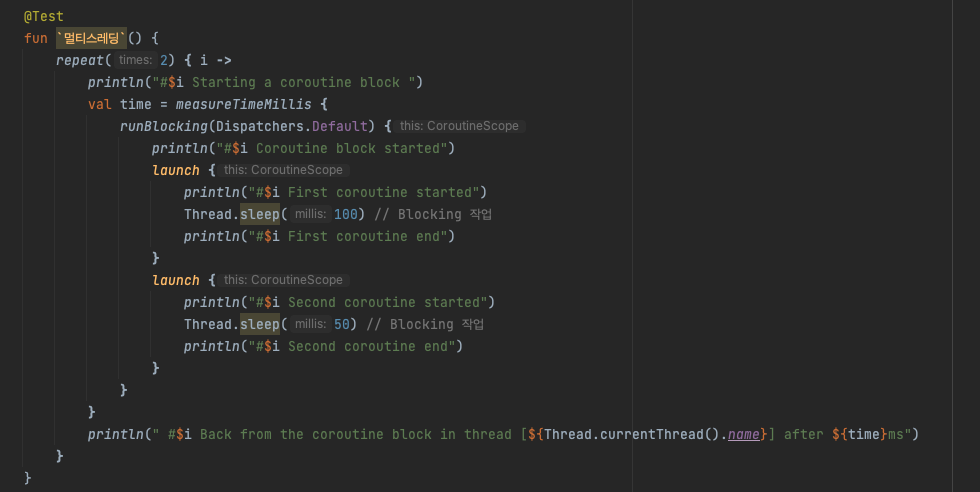
 결과
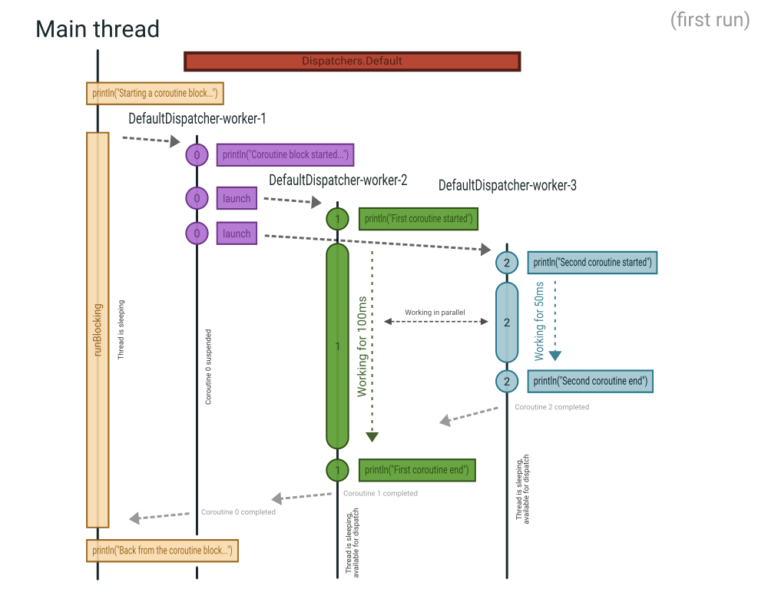
결과