데이터 플랫폼 구축기

전사 공용 데이터 플랫폼의 부재로 인해 데이터 통합, 인사이트 도출, 거버넌스 구축을 시도조차 할 수 없는 상황에 직면했다.
흩어진 데이터와 사일로화된 시스템들 사이에서 비즈니스 의사결정에 필요한 데이터를 확보하기 어려웠고, 각 팀마다 다른 도구와 방식으로 데이터를 다루며 일관성 있는 분석이 불가능했다.
이러한 문제를 해결하기 위해 시니어 DevOps 엔지니어 1명과 함께 전사 데이터 플랫폼 TF를 작게 시작했다. 기술 스택 선정, 아키텍처 설계, 구현 과정에서 마주한 도전과 해결책들을 단계별로 기록하여 같은 고민을 하는 팀들에게 도움이 되고자 한다.
데이터 엔지니어링의 첫걸음부터 운영 가능한 플랫폼까지, 작은 팀이 만들어가는 데이터 플랫폼 구축 여정을 공유한다.
요구사항 정의
우선순위 높은 순으로 정리하면 다음과 같다:
-
쇼핑몰 방문자 통계 기능 고도화 (일 8,000만 건 데이터)
-
주문 데이터 분석 (웹로그 기반)
-
고객 세분화
- 최근 6개월 가입 고객 중 3만원 이상 구매한 고객 데이터 추출
- 최근 일주일 장바구니에 담았으나 결제하지 않은 고객 데이터 추출
- 사용하지 않은 발급된 쿠폰을 보유한 고객 데이터 추출
-
플랫폼 통계
- 전체 앱 설치 수
- 전체 쇼핑몰 랭킹 (회원수, 상품수, 주문수 등)
1차 목표: 방문자 분석 고도화
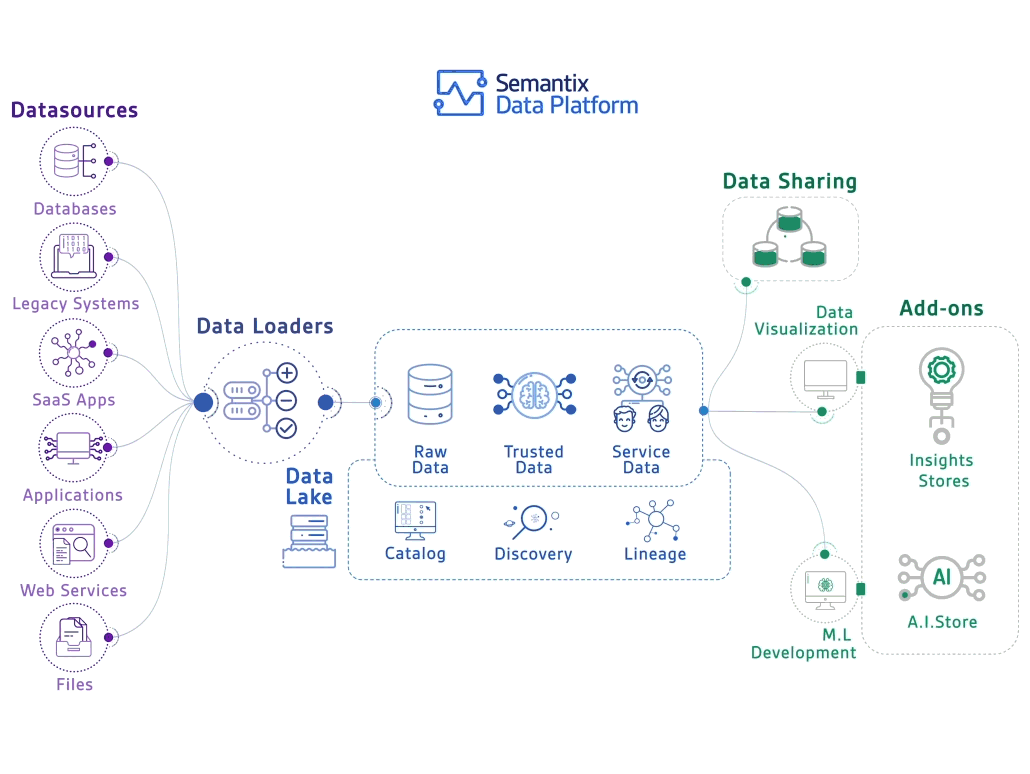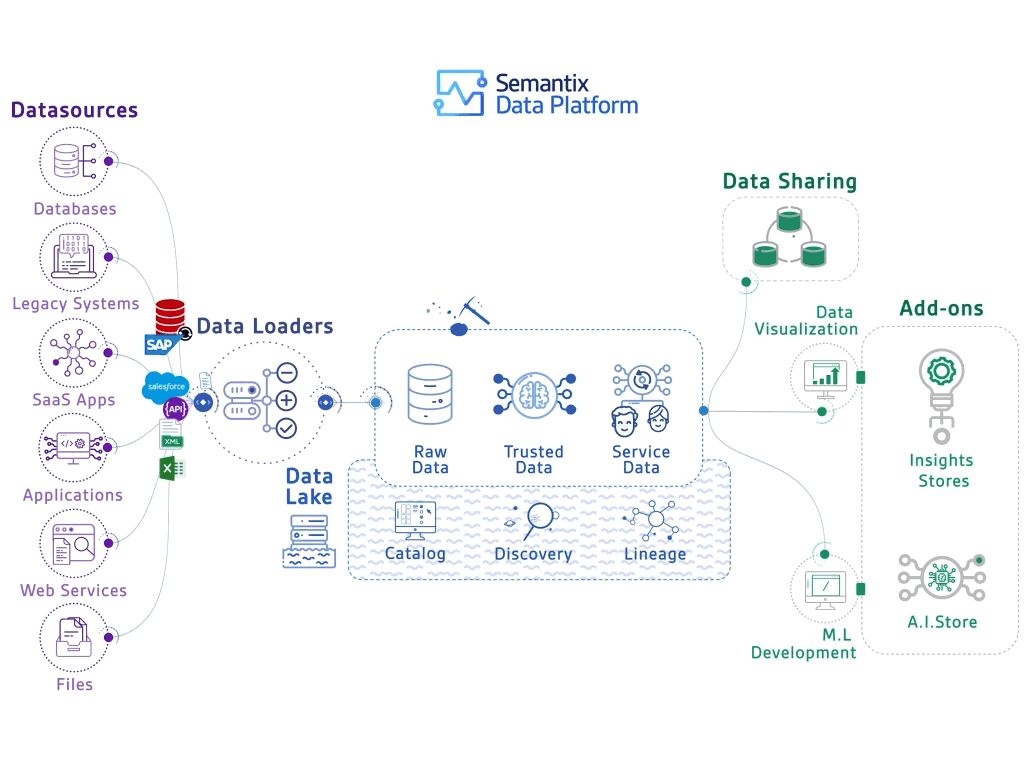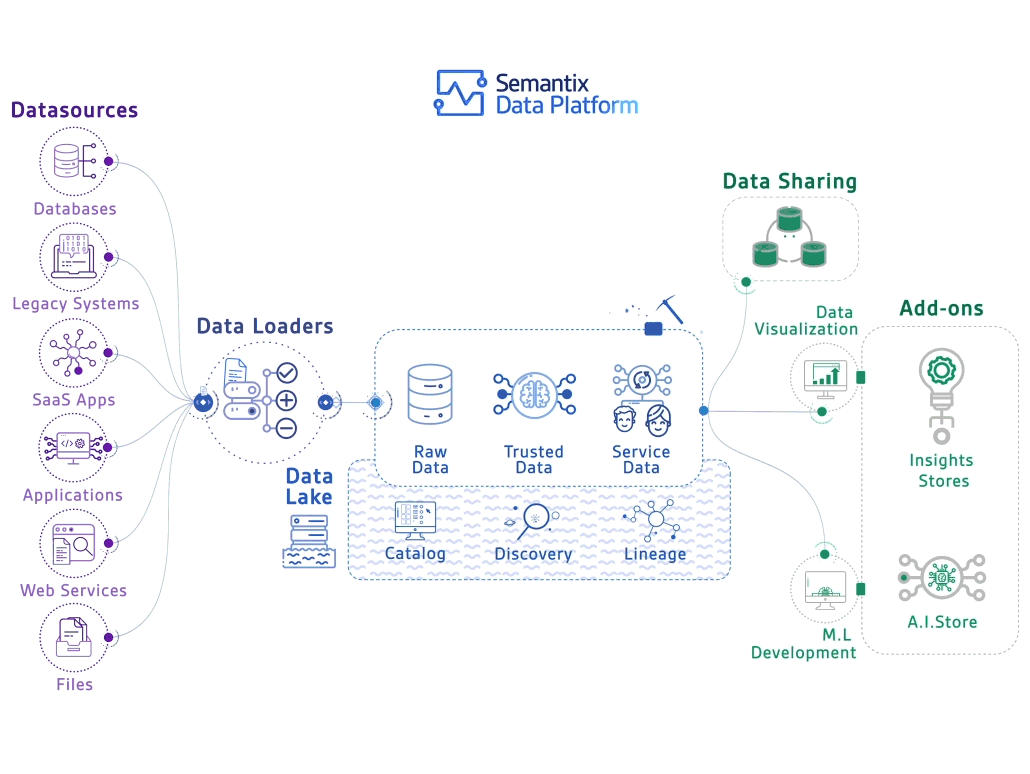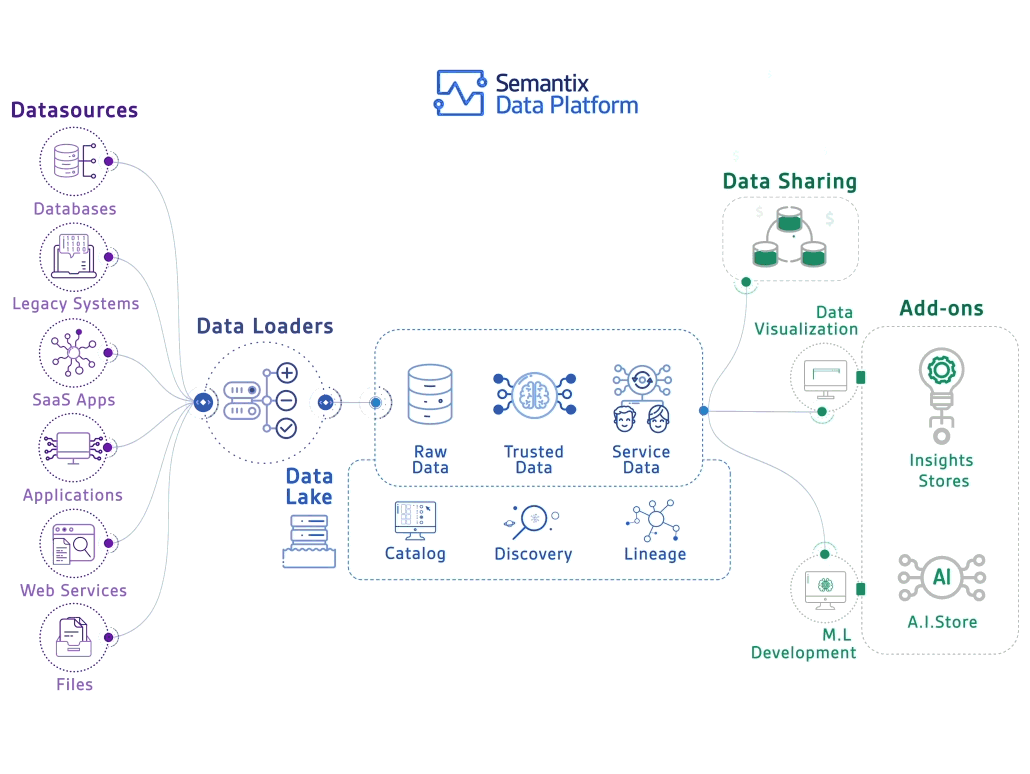
AS-IS 방문자 통계 아키텍처
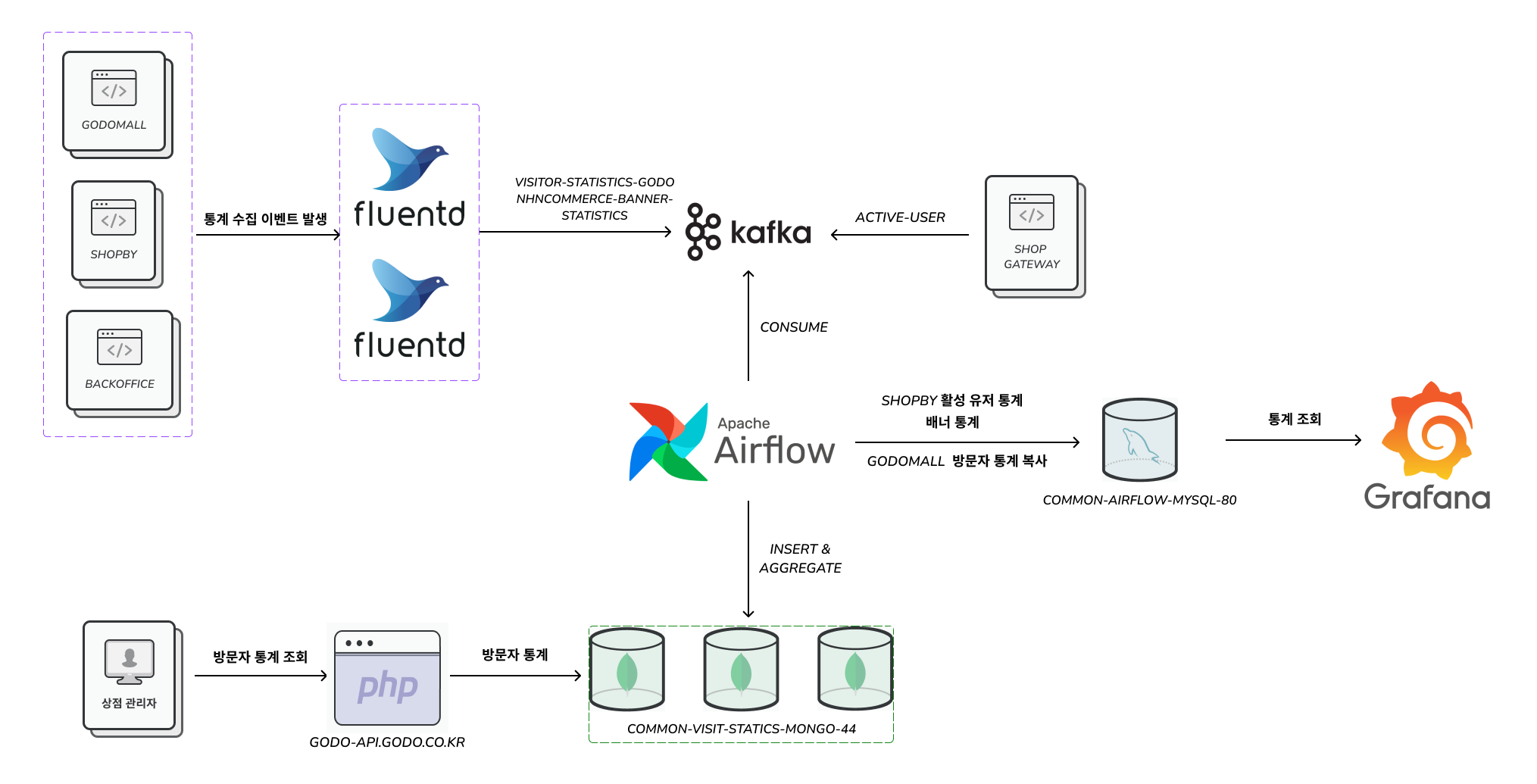
위 그림을 간단히 설명하면, Web → Fluentd → Kafka와 Gateway Server → Kafka로 구성되어 있다. 즉, 단일 진입점인 Kafka에 데이터(토픽)가 쌓이고 Airflow DAG을 통해 데이터 마트 DB인 MongoDB, MySQL에 적재하고 있다.
하지만 여기서 심각한 문제점들을 발견할 수 있다.
- 원본 데이터 유실: 웹로그 토픽의 리텐션이 3일밖에 되지 않아 원본 데이터가 사라진다
- Raw Data 저장소 부재: 가공되지 않은 원본 데이터를 영구 보관할 수 있는 데이터 레이크가 없다
- 제한적인 분석 범위: 과거 데이터 분석이나 장기적인 트렌드 분석이 불가능하다
- 데이터 재처리 불가: 비즈니스 요구사항이 변경되었을 때 과거 데이터를 다시 분석할 수 없다
결국 통합된 데이터 플랫폼의 부재로 인해 전사적인 데이터 활용이 제한되고 있는 상황이다.
TO-BE 아키텍처 계획
뛰어난 DevOps 시니어 엔지니어분과 의기투합하여 여러 번의 회의를 거쳐 아래와 같은 다이어그램으로 계획을 수립했다.
핵심 설계 원칙:
- 모든 데이터는 Kafka를 통해 진입
- Kafka Consumer를 통해 Iceberg에 CDC (Change Data Capture)
- Airflow DAG으로 주기적인 방문자 데이터 집계 (월/일/시간 단위)
- 데이터 마트는 기존과 동일한 스키마 구조로 MongoDB에 적재
- API 서빙은 FastAPI와 PySpark 활용

역할 분담:
- DevOps 엔지니어: Iceberg 설치, Fluentbit(Kafka output plugin), Spark 설치 및 설정, Python Kafka Consumer를 이용한 Iceberg 적재 로직
- 본인: Airflow DAG 개발, FastAPI 프로젝트 구성 및 API 개발
각 부서에서 데이터 플랫폼에 적재 및 집계하는 로직은 가이드를 만들어 개별 부서에서 진행할 수 있도록 했다. 데이터 플랫폼 TF는 한시적이며, 리소스 한계로 인해 확장 가능한 구조로 설계했다.
Airflow DAG 개발
파이썬의 경우 최근 AI 서비스 상품화 POC 준비와 파이썬 크롤러 프로젝트를 진행했어서 개발하는 데 큰 문제는 없었다.
기존 인프라 활용:
- DAG 실행 실패 시 Loki로 로그 전송
- 메신저 알람 기능
- MySQL, MongoDB 데이터 적재 로직
이미 동료들이 잘 만들어놓은 소스를 참고하여 개발을 진행했다.
워크플로우 제어: 외부 DAG의 실행 완료를 대기한 후, 일별/월별/TOP 방문자 통계를 병렬로 실행하는 구조로 설계했다.
# 예시 코드
wait = ExternalTaskSensor(
task_id="wait_for_visit_statics_per_mall",
external_dag_id="dataops_visitor_statistics_aggregation",
external_task_id="VS3_1-visit_statics_per_mall",
execution_date_fn=lambda x: x - timedelta(hours=5),
mode="poke", # 주기적으로 외부 태스크 상태 확인
poke_interval=60, # 60초마다 확인
on_failure_callback=DataopsDoorayHook().task_failure_alert,
dag=dag,
)
start >> wait
wait >> 일별_집계_DAG >> end
wait >> 월별_집계_DAG >> end
wait >> TOP방문자_DAG >> end
FastAPI 서버 개발
Data Mart를 서빙하는 REST API를 개발한다.
개발 계획
- Poetry, lint, formatter, VSCode, Python을 이용한 프로젝트 셋팅 ✅ 2025-03-13
- Pylint 적용 ✅ 2025-03-13
- Black 적용 ✅ 2025-03-07
- Poetry 셋팅 ✅ 2025-03-07
- VSCode 적용 (settings.json) ✅ 2025-03-07
- 프로젝트 구조화: 모듈, 설정, 패키지 구조 설계 ✅ 2025-03-07
- 로컬 실행과 테스트를 위한 Docker 구성, .env 스테이지 구분 ✅ 2025-03-07
- Pytest로 단위 테스트 코드 작성, HTTP 테스트
- DB connection & SQL 조회 (PySpark, Iceberg) ✅ 2025-03-07
- FastAPI에서 제공하는 OAS document
- PySpark 조회, MySQL 조회, MongoDB 조회 샘플 코드 작성 ✅ 2025-03-07
프로젝트 셋업
# 사전 설치 요구사항
# Python 3.11.0
# Poetry 2.1.1
poetry new data-platform-api
cd data-platform-api
poetry install
poetry add fastapi uvicorn sqlalchemy pydantic pydantic-settings python-dotenv pymysql pprintpp pyspark virtualenv setuptools pandas PyArrow grpcio protobuf grpcio-status jinja2
poetry add --group dev pytest ruff pytest-cov httpx
poetry env activate
which python # {workspaceDir}/.venv/bin/python
pre-commit-config.yaml에서 Ruff 정의
- repo: https://github.com/charliermarsh/ruff-pre-commit
rev: "v0.9.8"
hooks:
- id: ruff
args: ["--fix"]
types_or: [python, pyi]
- id: ruff-format
types_or: [python, pyi]
Ruff 룰 적용
.ruff.toml (formatter, lint, reorder 등 한 번에 해결)
lint.select = [
"E", # Pyflakes
"F", # Pycodestyle
"I", # isort
]
# 무시할 규칙
lint.ignore = ["E501"] # 줄 길이 제한 무시
# 줄 길이 설정
line-length = 80
VSCode 플러그인 설치 목록
- Ruff
- Even Better TOML
- Pylance
- Python
- Python Debugger
- REST Client
- SQLTools
- SQLTools MySQL/MariaDB
FastAPI Endpoint 설정
# main.py - K8S 헬스 체크용
@app.get("/readiness")
async def readiness_probe():
return {"status": "ok"}
# router.py - 도메인 단위로 추가
router = APIRouter()
router.include_router(
visitor_statistics_controller.router,
prefix="/analytics/visitors",
tags=["visitors"],
)
# visitor_controller.py
# Pydantic 응답 객체 항상 만들어서 반환
# SparkSession은 FastAPI의 DI 기능을 활용하여 의존성 주입
@router.get("/day", response_model=VisitorStatisticsDailyResponse)
async def read_visitor_by_day(
headers,
queryParams,
session: SparkSession = Depends(get_spark_session)
):
return VisitorStatisticsDailyResponse()
프로젝트 결과 및 회고
성과
- 개발 기간: 2개월
- 개발 결과물: Airflow DAG 9개, API Endpoint 20개
- 처리 성능: 일 최대 1억 건의 웹로그 데이터 성공적으로 적재, 집계, 서빙
경험
시간 분배: 코드 작성 시간보다 데이터 정합성 체크에 더 많은 시간을 소비했다. RDB에서 복잡한 통계 쿼리랑 별반 차이가 없는것 같다. (데이터 집계 정합도 맞추는 일은 매우 어려운 일이다.)
기술 스택 선택의 만족도:
- Iceberg
- 전문 데이터 엔지니어가 없는 상황 + AWS등 관리형 서비스를 사용할 수 없는 환경이라면 Iceberg가 hadoop보다 낫다고 판단하였음
- HDFS + Hive 기본 인프라 비용이 Iceberg에 비해 3배 이상이였음
- 로컬에서 MinIO를 이용해 쉽게 띄워 볼수 있으며 클라우드 상품인 Object Storage를 이용하면 스토리지 관리 비용이 매우 낮아짐
- FastAPI: Spring 경험이 있다면 금방 적응할 수 있었다.
- PySpark + Pandas: 데이터 처리와 엑셀 다운로드 구현이 놀랍도록 간단했다.
# 정말로 아래 한 줄로 엑셀 생성이 가능하다
pyspark_df.toPandas().to_excel("tmp.xlsx", index=False, engine="openpyxl")
최종 결과물
성공적으로 구축된 데이터 플랫폼을 통해 다음과 같은 분석 화면을 제공함
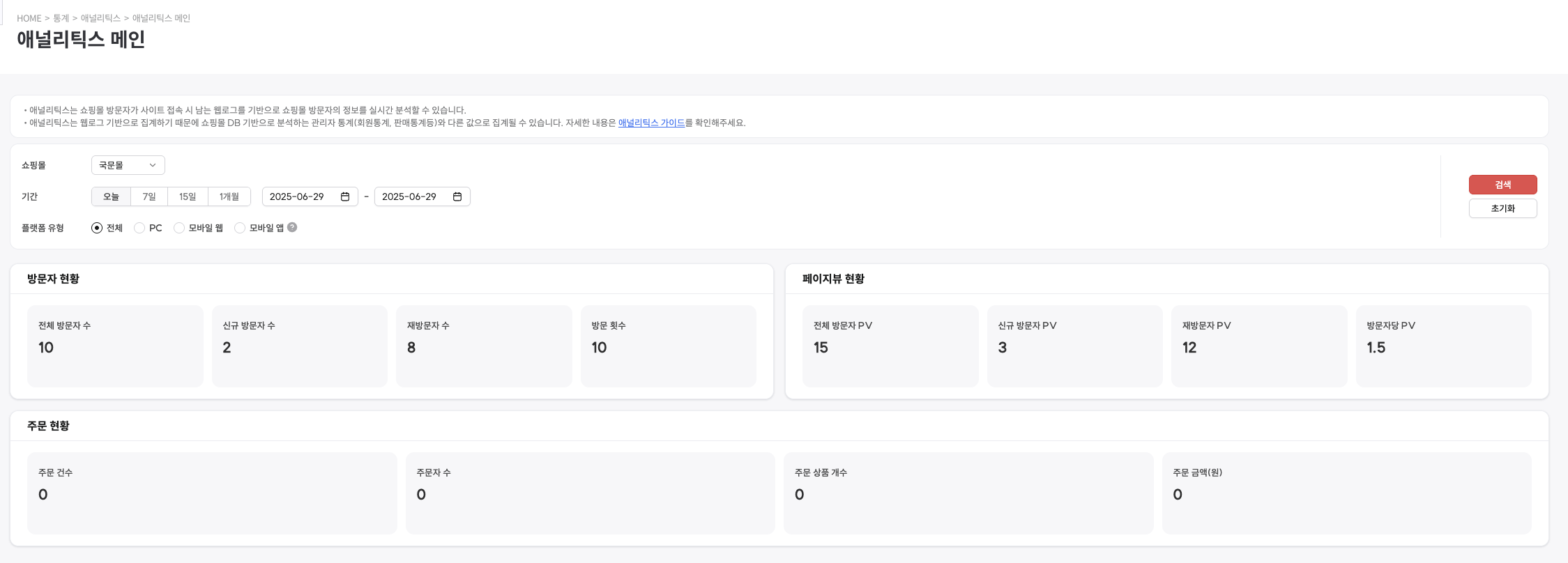
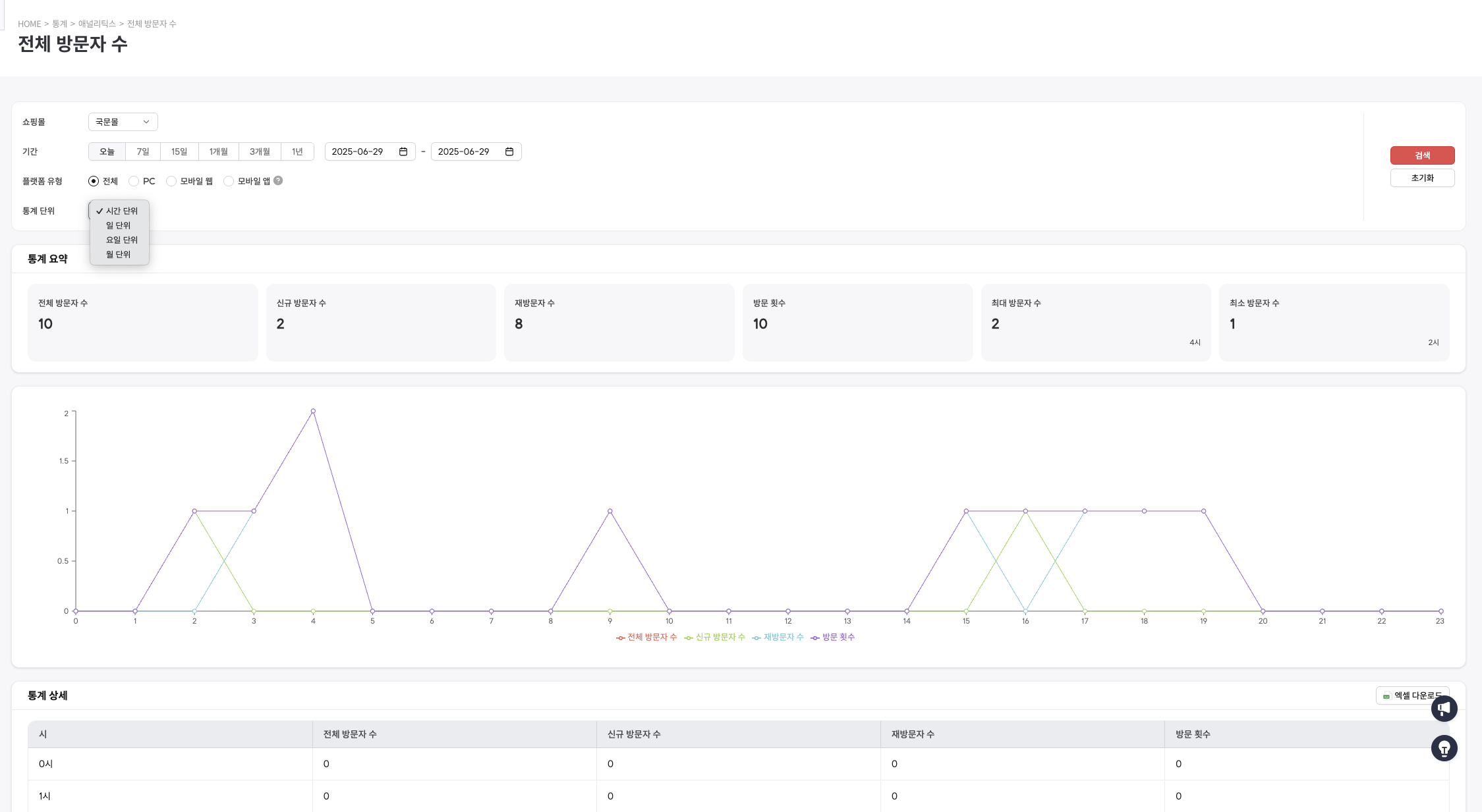
향후 개선 방향
- 확장성: 각 부서별 가이드를 통한 자율적 데이터 파이프라인 구축
- 모니터링: 데이터 품질 관리 및 알림 시스템 고도화
- 거버넌스: 데이터 접근 권한 및 보안 정책 수립
작은 팀으로 시작한 데이터 플랫폼 구축 프로젝트였지만, 체계적인 계획과 적절한 기술 스택 선택으로 성공적인 결과를 얻을 수 있었다. 같은 고민을 하는 팀들에게 도움이 되기를 바란다.
데이터 플랫폼의 이해 (타팀 공유 내용)
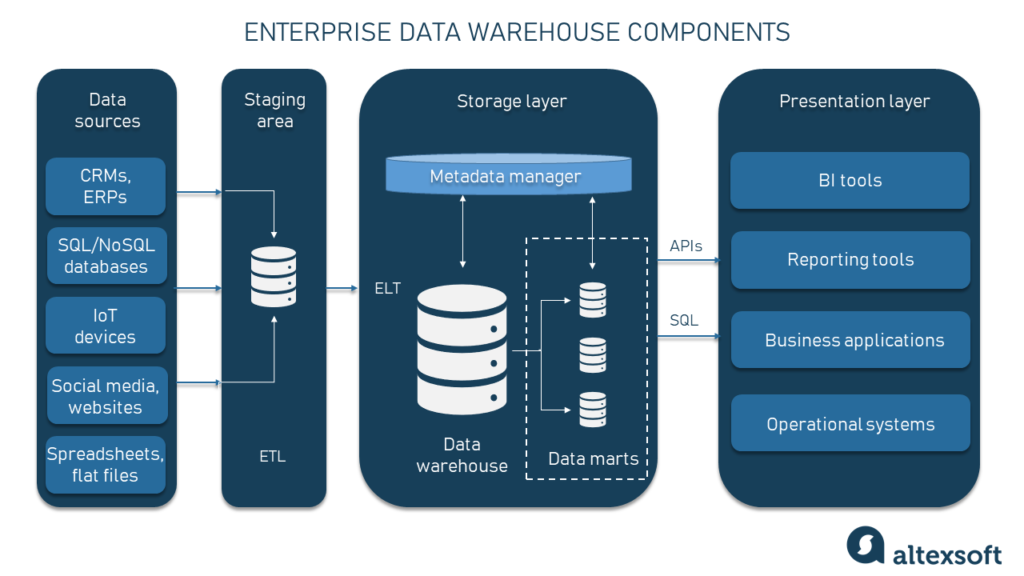
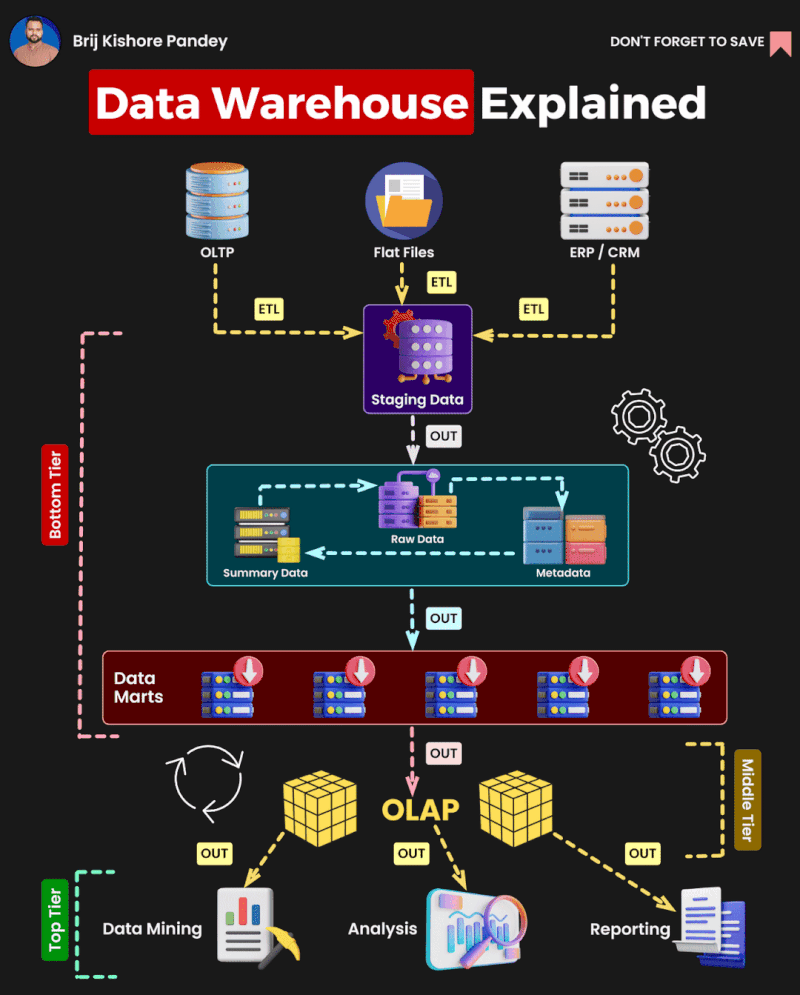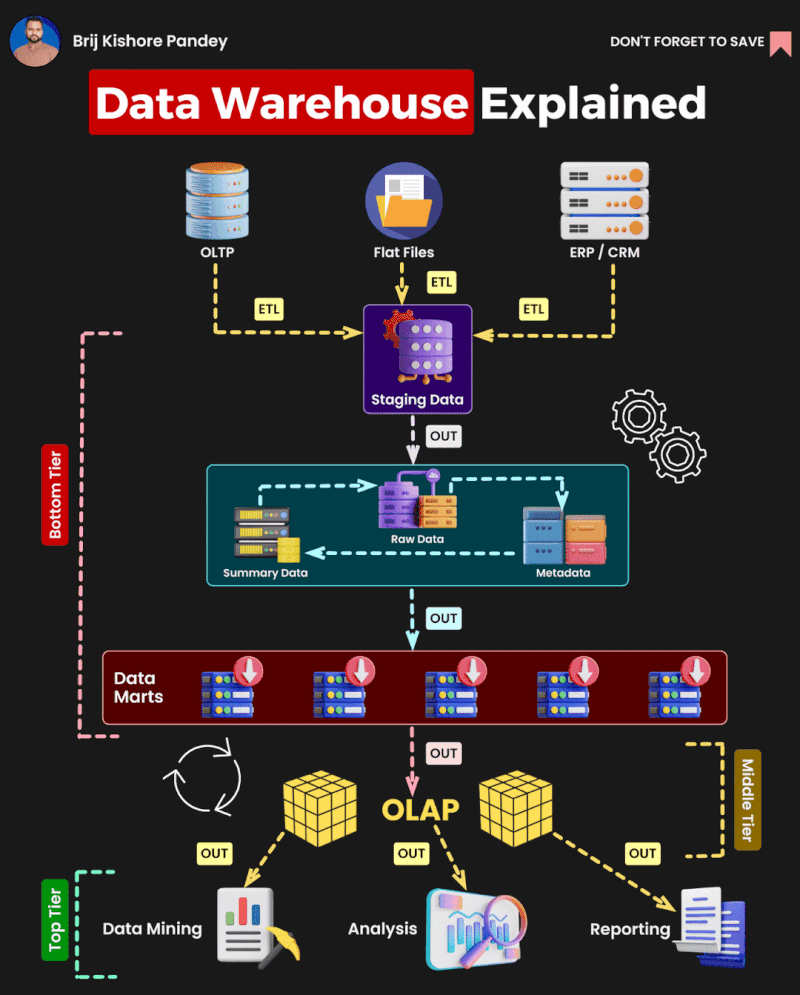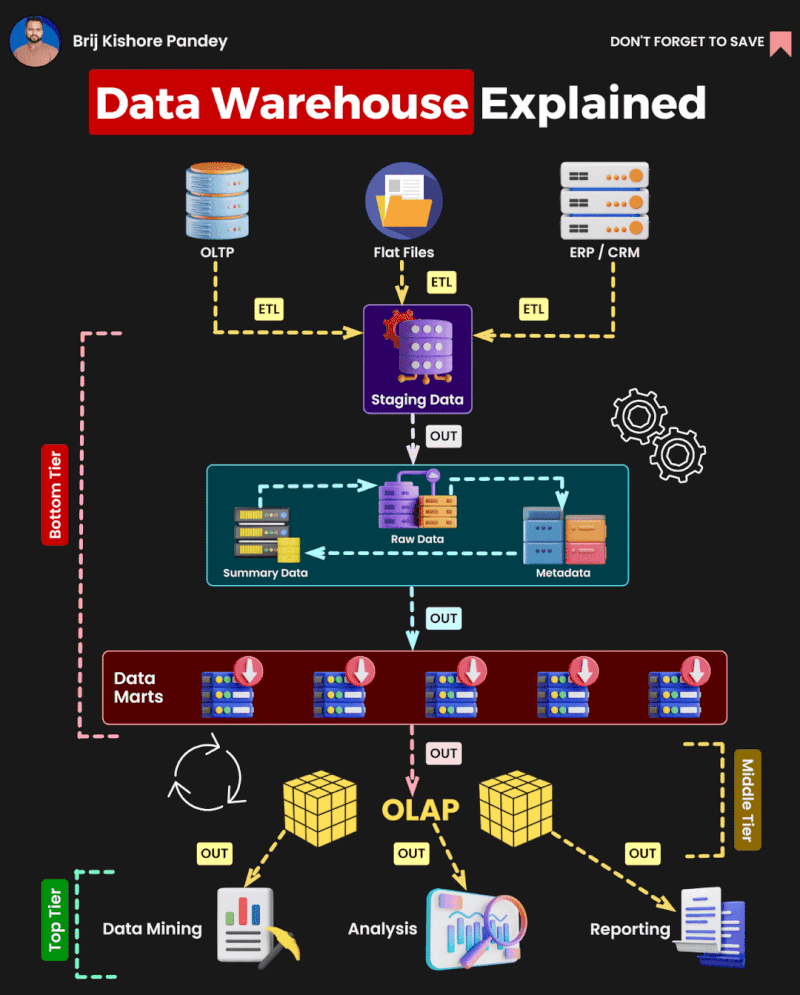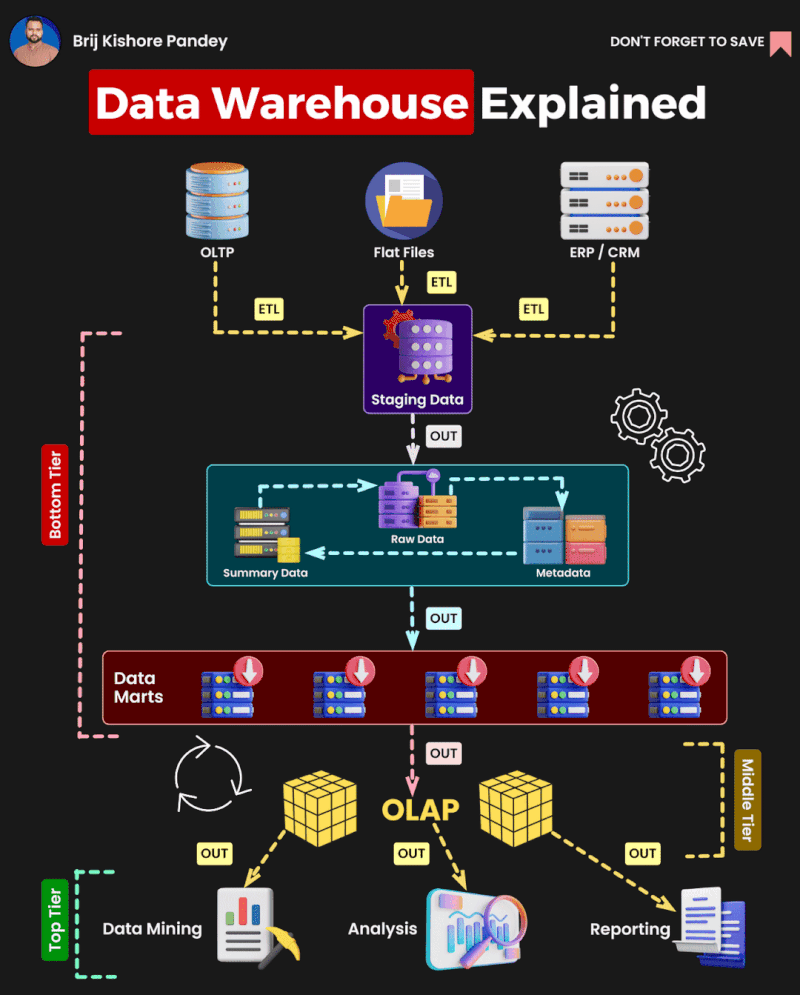
DW (Data Warehouse, 데이터 웨어하우스)
 출처
출처
 출처
출처
- 정의: 여러 소스에서 수집된 데이터를 통합하여 분석과 보고를 위해 구조화된 저장소.
- 특징:
- 주로 OLAP (Online Analytical Processing) 용도로 사용.
- 대량의 데이터를 저장하고, 주로 비즈니스 인텔리전스(BI) 및 분석에 활용.
- 데이터는 정제되고, 통합되며, 시간에 따라 변화하는 기록을 저장.
- 스키마는 주로 **정형화(Structured)**되어 있음
- 데이터 갱신 빈도 : 일정에 따른 주기적 수행, 실시간 수행과 유사한 빈도로 수행되는 방향으로 변하는 추세
- 사용 사례: 기업의 의사결정 지원, 보고서 생성, 트렌드 분석.
OLAP (Online Analytical Processing)
- 정의: 다차원 데이터를 분석하는 데 사용되는 기술.
- 특징:
- 주로 데이터 웨어하우스에서 사용.
- 복잡한 쿼리와 집계 작업에 최적화.
- 데이터는 읽기 중심이며, 대량의 데이터를 빠르게 분석.
- 예: 큐브(Cube)를 사용한 다차원 분석.
- 사용 사례: 비즈니스 인텔리전스, 데이터 분석
OLTP (Online Transaction Processing)
- 정의: 실시간 트랜잭션 처리를 위한 시스템.
- 특징:
- 주로 데이터베이스에서 사용.
- 빠른 읽기/쓰기 작업에 최적화.
- 데이터는 정규화되어 있으며, 작은 단위의 트랜잭션 처리.
- 예: 은행 거래, 주문 처리 시스템.
- 사용 사례: 실시간 트랜잭션 처리, 운영 시스템.
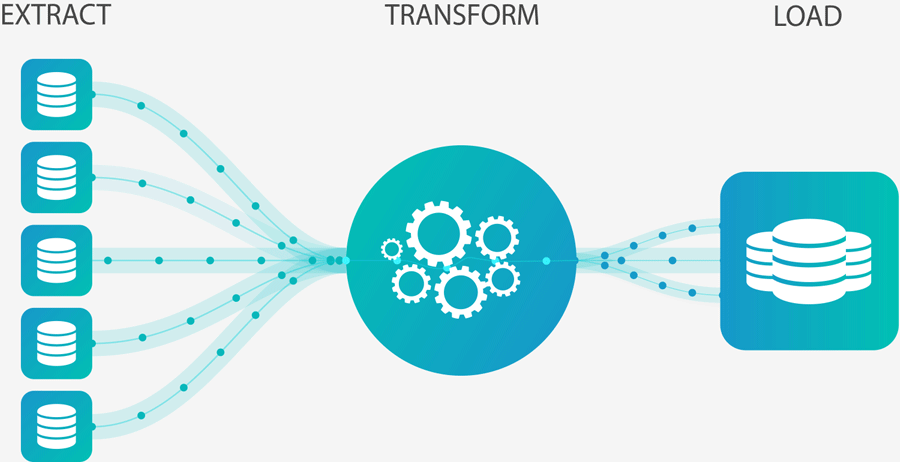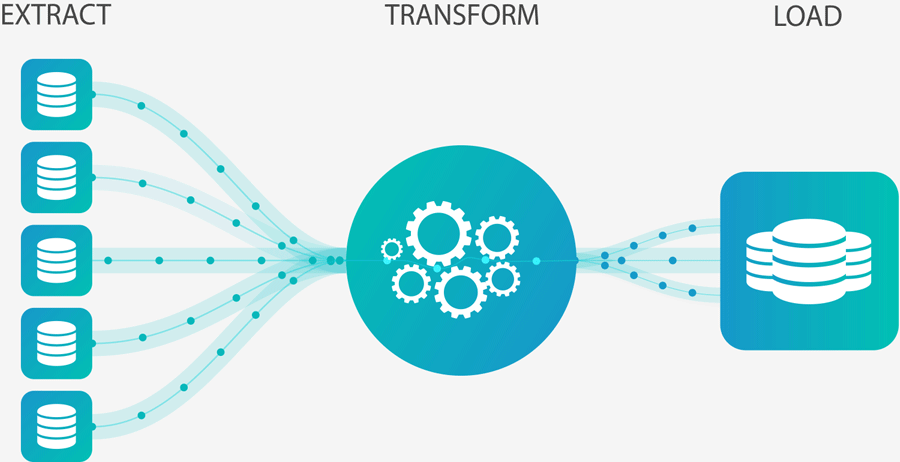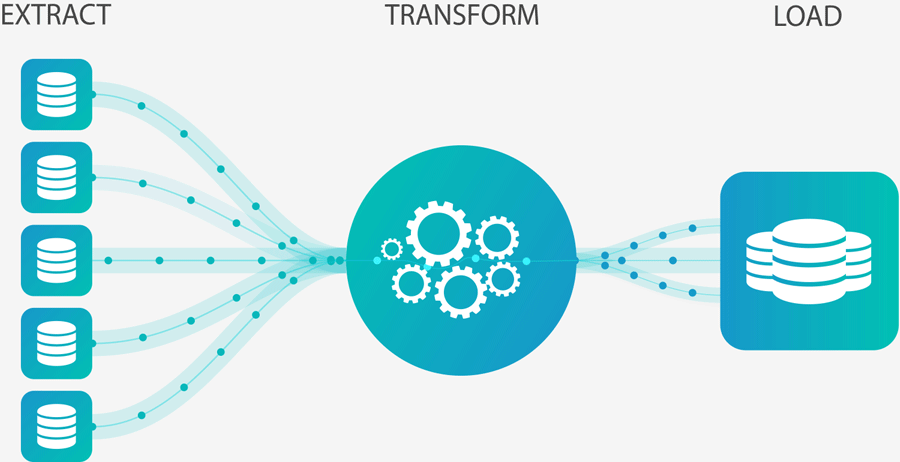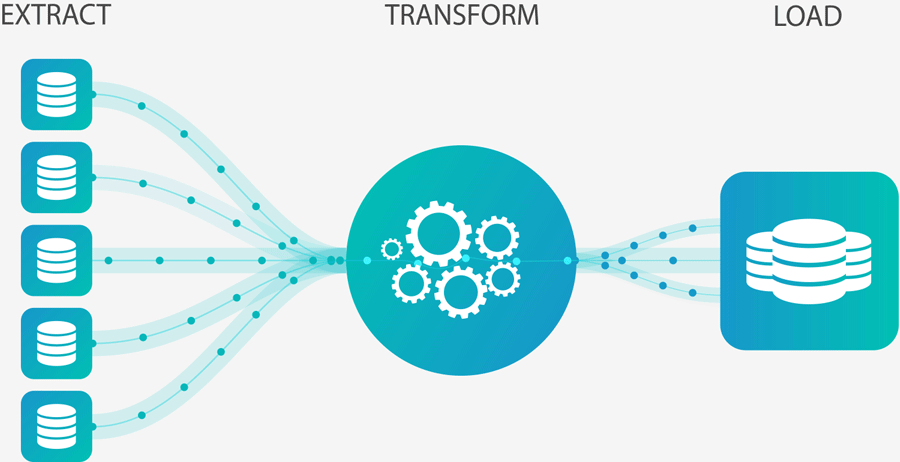
ETL (Extract, Transform, Load)
-
정의: 데이터를 소스에서 추출(Extract), 변환(Transform), 목적지에 로드(Load)하는 프로세스.
-
특징:
- 데이터 웨어하우스나 데이터 마트로 데이터를 이동시키는 데 사용.
- 변환(Transform): 데이터 정제, 통합, 필터링, 집계 등.
- 배치 처리 방식으로 주로 실행.
-
사용 사례: 데이터 웨어하우스 구축, 데이터 통합.
- 방문자 통계 RAW데이터
01-20 13:00:01 홈길동
01-20 13:00:02 홈길동
01-20 13:00:03 홈길동
01-20 13:00:02 뉴진스
01-20 13:00:03 뉴진스
01-20 13:01:01 홈길동
01-20 13:05:58 뉴진스
01-20 13:08:58 뉴진스
01-20 13:10:59 홍길동- 가공된 데이터
시간대 방문자수 방문횟수 13:00~14:00 2 9
Data Mart (데이터 마트)
- 정의: 특정 부서나 기능에 초점을 맞춘 소규모 데이터 웨어하우스.
- 특징:
- 데이터 웨어하우스의 부분집합.
- 특정 주제나 부서(예: 영업, 마케팅)에 맞춰 데이터를 제공.
- 데이터 웨어하우스보다 구축 비용이 낮고, 빠르게 구현 가능.
- 사용 사례: 부서별 분석, 특정 비즈니스 요구 사항 충족.
Data Lake (데이터 레이크)
- 정의:
정형(DB, 고정된 데이터), 반정형, 비정형(PDF, 이메일, 위키, html 크롤링등) 데이터를 원본 형태로 저장하는 대규모 저장소. - 특징:
- 스키마가 정의되지 않은 상태로 데이터 저장 (Schema-on-Read).
- 대량의 데이터를 저렴한 비용으로 저장 가능.
- 데이터 분석, 머신러닝, 실시간 처리 등 다양한 용도로 활용.
- Hadoop, AWS S3, Azure Data Lake 등이 대표적인 플랫폼.
- 사용 사례: 빅데이터 분석, 머신러닝 모델 학습.
4. ELT (Extract, Load, Transform)
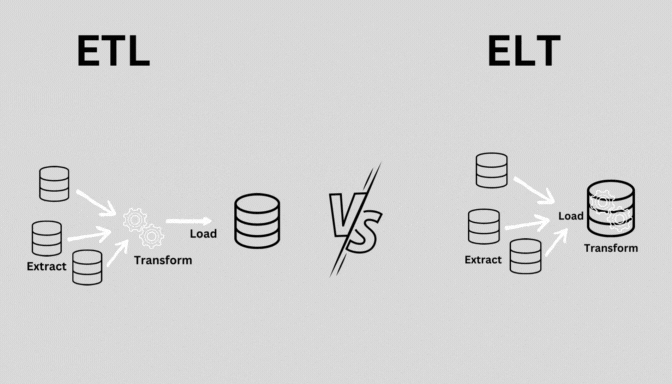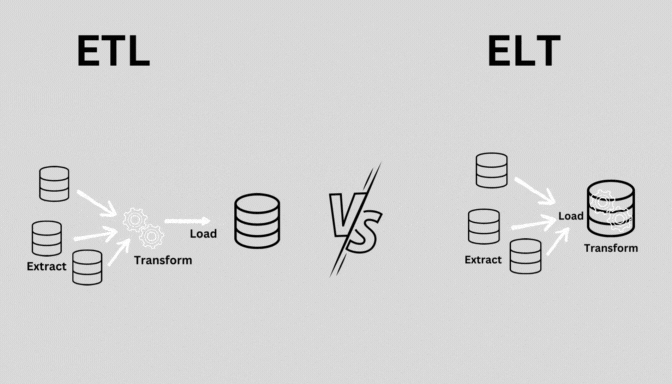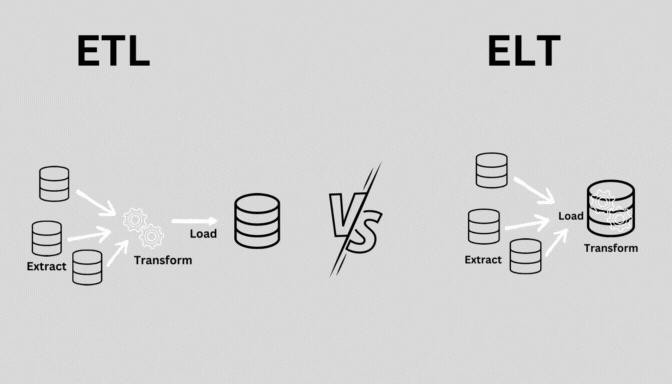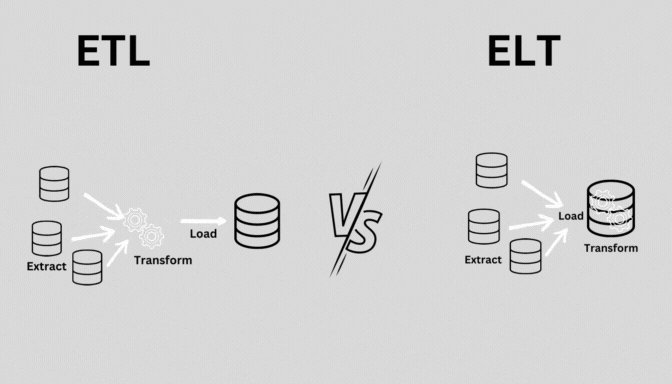
- 정의: 데이터를 추출(Extract)하고, 먼저 목적지에 로드(Load)한 후 변환(Transform)하는 프로세스.
- 특징:
- 클라우드 기반 데이터 웨어하우스나 데이터 레이크에서 주로 사용.
- ETL과 달리, 데이터를 먼저 로드한 후 필요에 따라 변환.
- 실시간 또는 근실시간 처리에 적합.
- 사용 사례: 클라우드 기반 데이터 분석, 실시간 데이터 처리
KAFKA
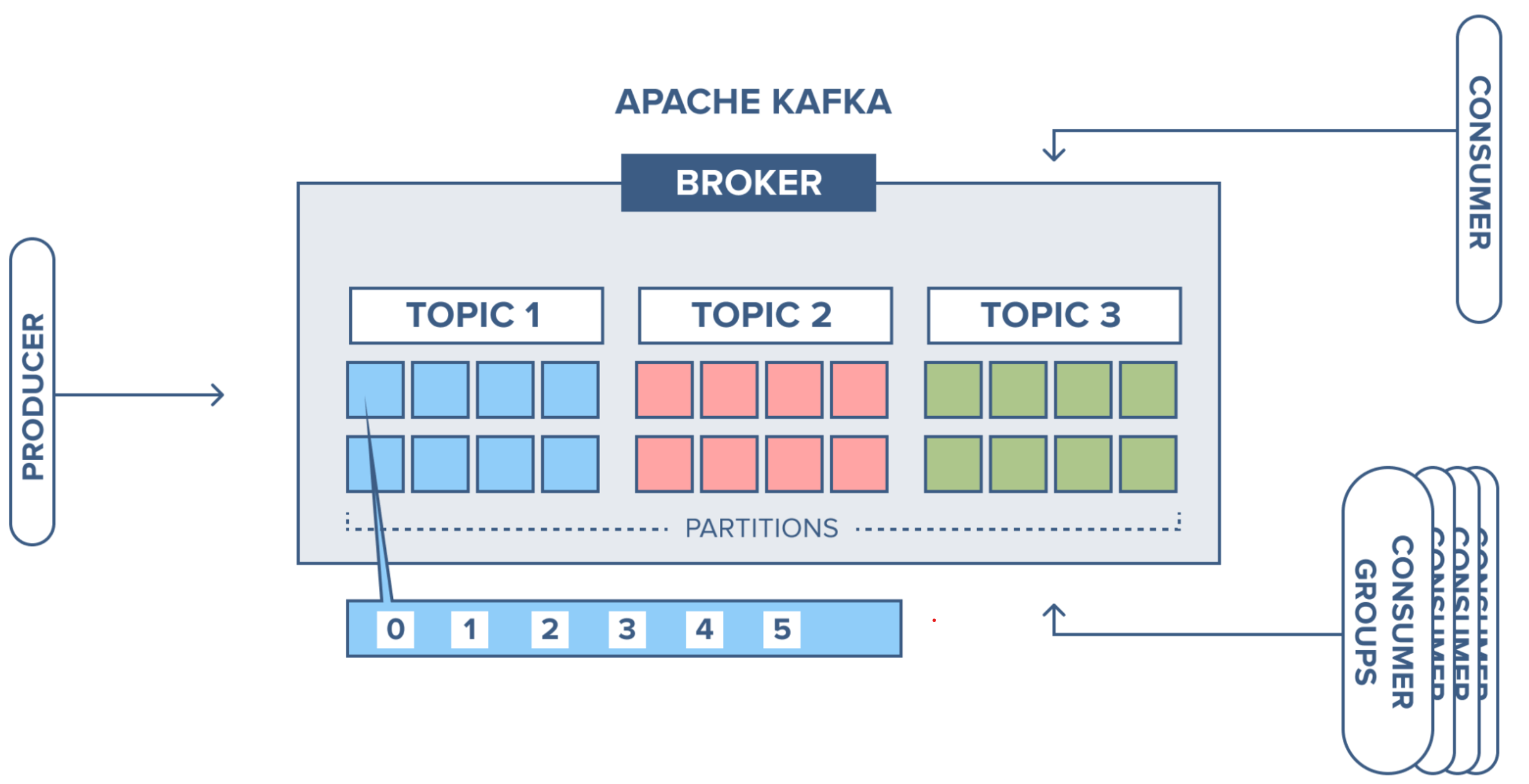
- 데이터 스트리밍을 위한 분산 메세징
- 초당 수백만건 처리 + 낮은 지연 -> 대용량 데이터 스트리밍
- 수평 확장
- 내결함성 : 자동복구, 클러스터
- 영속성 : 디스크에 저장
- 생산자보다 소비자의 속도가 비슷하거나 더 빠르면 실시간에 가깝고 소비자의 속도가 더 느리면 실시간은 아니지만
최종 일관성(Eventual Consistency)을 보장
CDC
"CDC 복제"는 데이터베이스나 데이터 관리 시스템에서 사용되는 용어로, **Change Data Capture (CDC)**의 약자입니다. CDC는 데이터베이스에서 발생한 변경 사항(삽입, 업데이트, 삭제 등)을 실시간으로 추적하고 복제하는 기술을 의미합니다. 이를 통해 원본 데이터베이스의 변경 사항을 다른 시스템이나 데이터 저장소에 동기화할 수 있습니다.
CDC 복제의 주요 특징:
- 실시간 동기화: 데이터 변경이 발생하면 즉시 추적되어 복제됩니다.
- 효율성: 전체 데이터를 복제하는 대신 변경된 부분만 전송하므로 리소스 사용이 효율적입니다.
- 데이터 일관성: 원본과 복제본 간의 데이터 일관성을 유지할 수 있습니다.
- 다양한 사용 사례: 데이터 웨어하우징, ETL(Extract, Transform, Load), 백업, 분석 등에 활용됩니다.
FLINK
Apache Flink는 분산 데이터 처리 및 스트리밍 데이터 처리 프레임워크로, 실시간 데이터 분석 및 배치 처리를 위한 강력한 도구
- 실시간 데이터 스트리밍 처리
- 진정한 스트리밍 방식: 데이터를 배치 단위로 처리하지 않고 이벤트가 발생하는 즉시 처리.
- 저지연 및 고처리량: 실시간 데이터 파이프라인과 애플리케이션을 구축하기에 적합.
- 상태 기반 처리 (Stateful Processing)
- 상태 관리 기능: 복잡한 상태를 유지하면서 이벤트를 처리.
- 내결함성: 체크포인트와 상태 백업을 통해 장애 발생 시 복구 가능.
- Event Time 처리: 데이터의 발생 시간(Event Time)을 기준으로 정확한 결과를 계산.
- 일관된 배치 및 스트리밍 처리
- 하나의 엔진, 두 가지 처리 방식: 배치 작업과 스트리밍 작업을 동일한 코드와 모델로 처리 가능.
- Unified API: 동일한 API를 사용하여 스트리밍 및 배치 데이터를 처리.
- 유연한 배포 옵션
- 클러스터 기반 분산 처리: Apache Hadoop, Kubernetes, Docker 등의 환경에서 클러스터 실행 가능.
- 다양한 배포 모드: Standalone, YARN, Kubernetes 등 다양한 모드를 지원.
- 강력한 커넥터와 통합
- 다양한 데이터 소스/싱크 지원: Kafka, Cassandra, Elasticsearch, JDBC, AWS Kinesis 등과 통합 가능.
- 사용자 정의 커넥터: 특정 요구 사항에 맞게 커넥터를 커스터마이징 가능.
- 고급 분석 기능
- SQL 및 Table API: 표준 SQL을 사용하여 데이터를 처리하고 분석.
- 고급 데이터 처리: 머신 러닝, 그래프 분석, CEP(Complex Event Processing) 등 고급 데이터 처리 기능 제공.
- 내결함성 및 확장성
- 체크포인트: 중단된 작업을 재개할 수 있는 체크포인트 기능 제공.
- 확장성: 분산 아키텍처를 기반으로 수평 확장이 용이.
- 오픈소스 및 커뮤니티 지원
- 오픈소스 프레임워크: 무료로 사용 가능하며, 지속적으로 커뮤니티에서 개선 및 업데이트.
- 활발한 생태계: 다양한 플러그인 및 추가 도구 사용 가능.

Apache Iceberg
Apache Iceberg는 대규모 데이터를 저장하고 관리하는 데 특화된 테이블 형식(table format). Iceberg는 이론적으로 수십 페타바이트(PB) 이상의 데이터를 저장할 수 있으며, 수조(trillions) 건의 레코드를 처리함. 이는 Iceberg가 분산 스토리지 시스템(예: HDFS, S3, GCS)과 통합되어 있고, 데이터를 효율적으로 관리하기 위한 설계되어 있음.
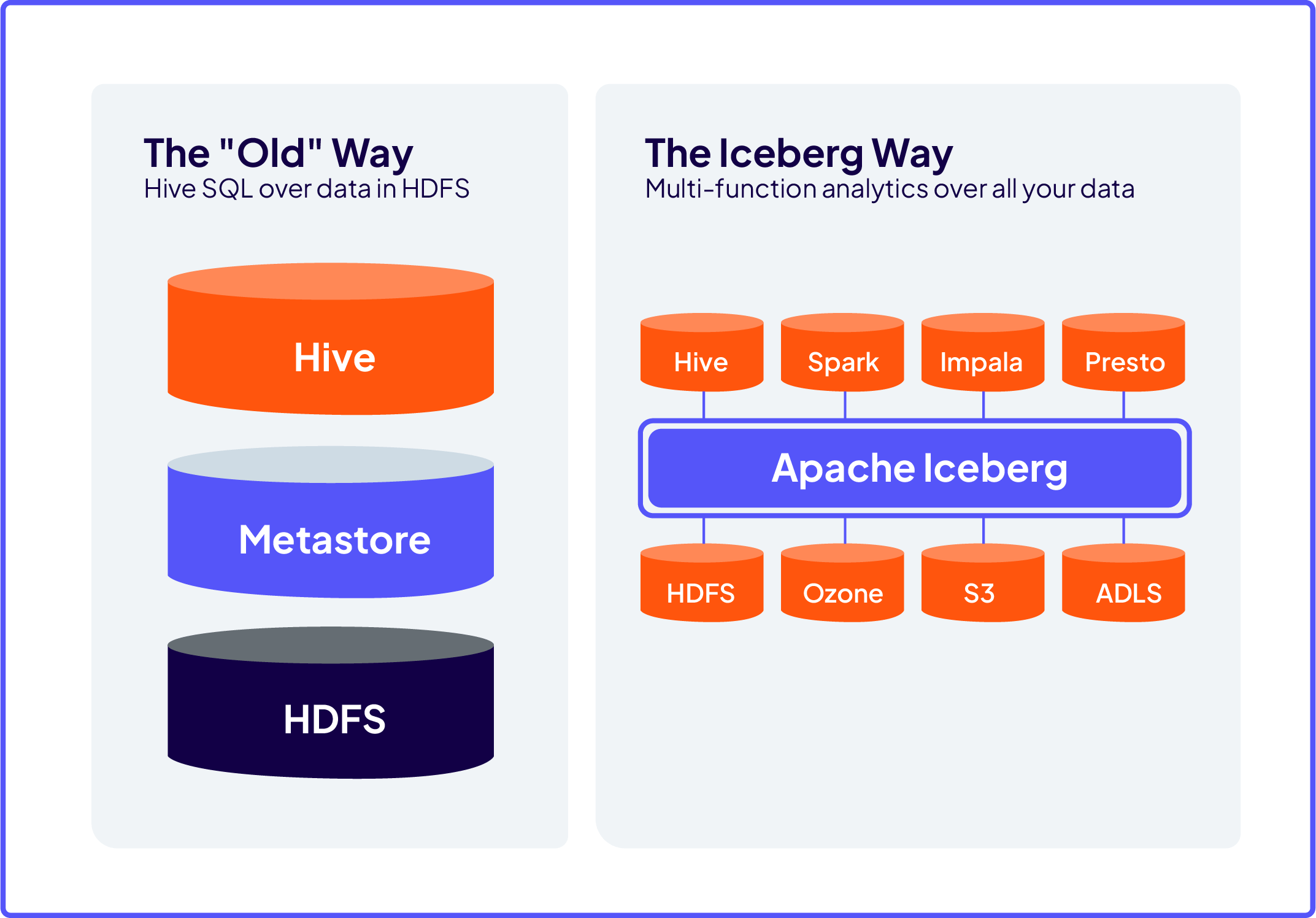
Expressive SQL Iceberg는 새 데이터를 병합하고, 기존 행을 업데이트하고, 대상 삭제를 수행할 수 있는 유연한 SQL 명령을 지원합니다. Iceberg는 읽기 성능을 위해 데이터 파일을 열심히 다시 쓰거나 더 빠른 업데이트를 위해 삭제 델타를 사용할 수 있습니다.
Full Schema Evolution
-
Add Column : 기존 데이터는
null값 -
Drop Column : 물리적으로 삭제 X, Metadata에서만 제거
-
Rename Column : 기존 데이터 영향 X
-
Update Column Type : INT -> BIGINT 가능
-
Reorder Columns : 컬럼 순서 변경
-
특징
- 하위 호환성
- 컬럼을 삭제해도 삭제 전 데이터는 읽을 수 있다. (삭제 전 데이터는 테이블 스키마도 삭제 전 스키마)
- 상위 호환성
- 새로운 컬럼이 추가되어도 이전 버전의 클라이언트는 해당 컬럼을 무시하고 읽을 수 있습니다.
- 메타데이터
- 스키마 변경시 데이터는 수정X, 메타데이터만 업데이트
- 스키마 변경이 빠르고 효율적
- 하위 호환성
Hidden Partitioning
-- ICEBERG
-- 테이블 생성 (Hidden Partitioning 적용)
CREATE TABLE iceberg_table (
id BIGINT,
event_time TIMESTAMP
) PARTITIONED BY (days(event_time));
-- 데이터 삽입
INSERT INTO iceberg_table VALUES (1, '2023-10-01 10:00:00'), (2, '2023-10-02 11:00:00');
-- 쿼리 (파티션 프루닝 적용)
SELECT * FROM iceberg_table WHERE event_time = '2023-10-01';
-- ORACLE DB
CREATE TABLE sales (
sale_id NUMBER,
sale_date DATE,
amount NUMBER
)
PARTITION BY RANGE (sale_date) (
PARTITION p1 VALUES LESS THAN (TO_DATE('2023-01-01', 'YYYY-MM-DD')),
PARTITION p2 VALUES LESS THAN (TO_DATE('2023-02-01', 'YYYY-MM-DD')),
PARTITION p3 VALUES LESS THAN (TO_DATE('2023-03-01', 'YYYY-MM-DD'))
);
Time Travel and Rollback
SELECT count(*) FROM nyc.taxis
2,853,020
SELECT count(*) FROM nyc.taxis FOR VERSION AS OF 2188465307835585443
2,798,371
SELECT count(*) FROM nyc.taxis FOR TIMESTAMP AS OF TIMESTAMP '2022-01-01 00:00:00.000000 Z'
2,798,371
Data Compaction Data Compaction은 데이터 파일의 수를 줄이고 파일 크기를 최적화하여 쿼리 성능을 향상시키는 프로세스를 의미 SQL명령어 또는 API를 이용하여 정의
CALL catalog_name.system.rewrite_data_files(
table => 'db.table_name',
strategy => 'binpack', -- 파일 크기를 균일하게 조정
options => map('min-file-size', '128MB', 'max-file-size', '512MB')
);
from pyspark.sql import SparkSession
# Spark 세션 생성
spark = SparkSession.builder \
.appName("Iceberg Data Compaction with PySpark") \
.master("local[*]") \ # 로컬 모드 실행
.config("spark.sql.catalog.my_catalog", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.my_catalog.type", "hadoop") \
.config("spark.sql.catalog.my_catalog.warehouse", "file:///path/to/warehouse") \ # 웨어하우스 경로 지정
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.getOrCreate()
# Data Compaction 실행
compaction_result = spark.sql("""
CALL my_catalog.system.rewrite_data_files(
table => 'my_db.my_table',
strategy => 'binpack', -- 파일 크기를 균일하게 조정
options => map('min-file-size', '128MB', 'max-file-size', '512MB')
)
""")
# Compaction 결과 출력
compaction_result.show()
# Spark 세션 종료
spark.stop()
SQL 엔진 없음 : Iceberg는 테이블 포멧일 뿐이다!.
- 주요 SQL엔진
- Apache Spark : spark.sql("SELECT * FROM iceberg_table")
- Apache Trino : SELECT * FROM iceberg_catalog.iceberg_table
- Apache Flink : Flink SQL을 통해 Iceberg 테이블을 쿼리할 수 있습니다.
- Apache Hive : HiveQL로 쿼리
- 클라우드 상품들 : SnowFlake, AWS Athena, Google BIgQuery,
자체 스토리지 없음 : 다양한 저장소 지원 : HDFS, S3, LocalFileSystem 등등.
Data Lakehouse 조사 자료 (데이터 운영파트 제공)
- 데이터 레이크(Data Lake)와 데이터 웨어하우스(Data Warehouse)의 장점을 결합한 데이터 아키텍처
- 데이터 레이크의 유연성과 데이터 웨어하우스의 성능 및 관리 기능을 모두 제공
제품별 기능 비교
| 기능 | Apache Hudi | Apache Iceberg | Delta Lake |
|---|---|---|---|
| 주요 사용 사례 | 빠른 데이터 업데이트, 스트리밍, ETL | 대규모 분석, 스키마 진화 | ACID 트랜잭션, 데이터 품질, Spark 통합 |
| 데이터 업데이트 | Upsert 및 Delete 지원 | 행 수준 업데이트 지원 | 업데이트 및 삭제 지원 |
| 성능 | 저지연 업데이트에 최적화 | 대규모 분석에 최적화 | Spark 워크로드에 최적화 |
| 파티셔닝 | 사용자 정의 파티셔닝 지원 | 자동 숨김 파티셔닝 (Hidden Partitioning) | 사용자 정의 파티셔닝 지원 |
| 스키마 진화(Schema Evolution) | 스키마 진화 지원 | 복잡한 스키마 진화 지원 | 제약 조건이 있는 스키마 진화 지원 |
| 시간 여행(Time Travel) | 제한적, 증분 쿼리 기반 | 고급 시간 여행 기능 지원 | 강력한 시간 여행 기능 지원 |
| 통합 | Spark, Hive, Flink와 잘 연동 | Spark, Presto, Flink 등 광범위한 지원 | Spark에 최적화된 성장 생태계 |
| 커뮤니티 | 성장 중, 상업적 지원 | 주요 클라우드 플랫폼에서 지원 | Databricks 및 Spark 커뮤니티의 강력한 지원 |
Apache Iceberg
- 스키마 진화 (Schema Evolution): 데이터 파일을 재작성하지 않고도 스키마 변경 가능
- 시간 여행 (Time Travel): 과거 데이터 버전을 쿼리 가능, 감사 및 디버깅에 유용
- 파티셔닝 최적화: 데이터 스캔을 최소화하여 쿼리 성능 향상
- 메타데이터 분리: 데이터 관리 안정성 및 복구 용이성 제공
- 동시 쓰기 지원: 여러 사용자 및 프로세스의 데이터 동시 작성 가능
- 다양한 통합: Spark, Flink, Hive, Presto 등과 연동
Apache Hudi
- 증분 처리: 변경된 데이터만 관리, 실시간 데이터 처리에 적합
- 쓰기 최적화: MOR(읽기 병합) 지원으로 지연 감소
- 인덱싱: 업데이트 및 삭제 작업 성능 개선
- 데이터 버전 관리: 디버깅 및 롤백을 위한 버전 기록 유지
- 스트리밍 지원: Flink, Kafka와 원활히 연동
Delta Lake
- ACID 트랜잭션: 데이터 정합성 보장
- 시간 여행(Time Travel): 특정 시점의 데이터 쿼리 가능
- 배치 및 스트리밍 통합: 두 작업을 하나의 플랫폼에서 처리
- 스키마 강제 및 진화(Schema Evolution): 강력한 스키마 제어 및 유연성 제공
- 성능 최적화: 데이터 건너뛰기 및 Z-정렬 인덱싱 지원
레퍼런스
토스
https://toss.tech/article/datalake-iceberg
- 실시간으로 수집되는 데이터를 저장하는 Iceberg 테이블은 모두 MOR(Merge-On-Read) 형식을 사용
- DW에서 사용하는 배치 작업으로 생성되고 유지 관리되는 Iceberg 테이블은 COW(Copy-On-Write) 형식을 사용
도입 시 고려 사항
- 주요 분석 엔진은 Impala 사용으로 Delta Lake는 호환성 부족
- Hudi 의 경우 읽기와 쓰기에 필요한 리소스가 Iceberg에 비해 더 많이 필요했으며, 성능 또한 만족스럽지 않음
라인
https://speakerdeck.com/line_devday2021/adopting-apache-iceberg-on-line-data-platform hive -> iceberg로 변경한 사례
카카오
https://tech.kakao.com/posts/656 CDC 비효율 개선, Spark 성능 제약 개선
11번가
https://techtalk.11stcorp.com/2023/session/session13.html
도입시 고려사항
- 실시간 Upsert 및 Delete 기능 & 성능을 타겟으로 검토
- 소규모 테이블 + 스트리밍 처리에 특화된 Hudi를 선정하였으나 스트리밍 처리시 delete 기능 미 작동으로 인해 Iceberg로 변경
구성
| 구분 | 데이터 레이크 | Apache Iceberg | 데이터 엔진 (예: Spark) |
|---|---|---|---|
| 역할 | 데이터를 저장하는 중앙 저장소 | 데이터 레이크의 데이터를 관리하고 최적화 | 데이터를 읽고 처리하며 분석 작업을 수행 |
| 주요 기능 | - 비구조적/구조적 데이터 저장 - 대규모 데이터 지원 | - 테이블 포맷 제공 - 메타데이터 관리 - 스키마 진화 및 버전 관리 - ACID 트랜잭션 지원 | - 데이터 처리 및 변환 - SQL 쿼리 - 머신러닝, 스트리밍 작업 |
| 저장소 | Amazon S3, GCS, Azure ADLS, HDFS 등 | 데이터 레이크의 메타데이터를 관리하고 최적화 | 데이터 레이크와 Iceberg 메타데이터를 활용하여 데이터를 처리 |
| 데이터 저장 형식 | Parquet, Avro, ORC 등 | 데이터 파일과 관련된 메타데이터 및 테이블 구조 관리 | Iceberg 메타데이터를 통해 필요한 데이터만 읽어 처리 |
| 스키마 관리 | 데이터 스키마를 직접 관리해야 함 | 스키마 진화 지원(컬럼 추가, 삭제, 변경 등) | Iceberg에서 관리된 스키마를 활용하여 데이터 작업을 수행 |
| 트랜잭션 지원 | 지원하지 않음 | ACID 트랜잭션 지원 | Iceberg의 트랜잭션 관리 기능을 활용 |
| 성능 최적화 | 제공하지 않음 | 파티셔닝 최적화, 쿼리 프루닝, 스냅샷 관리 등을 통해 데이터 접근 성능 향상 | Iceberg 메타데이터 기반으로 최적화된 데이터 작업 수행 |
| 상호 관계 | 데이터를 물리적으로 저장 | 데이터 레이크의 데이터를 체계적으로 관리 | Iceberg에서 관리한 데이터를 읽고 처리 |
| 비유 | 문서를 저장하는 보관함 | 문서를 체계적으로 정리하고 색인을 제공하는 관리 시스템 | 문서를 읽고 분석하며 처리하는 도구 |
Iceberg는 라이브러리 형태로 동작